Table of Contents
When people talk about control in SMS, the conversation often becomes misleading.
Because the truth is simple:
Once a message leaves your own infrastructure and enters the downstream delivery chain, you no longer control every step of its journey.
At that point, the message depends on external networks, partners, routing paths, and carrier-side conditions.
So what does full control actually mean in SMS?
It does not mean controlling the entire telecom ecosystem after handoff.
It means having complete control over everything that happens on your side before the message leaves your system.
And that distinction matters.
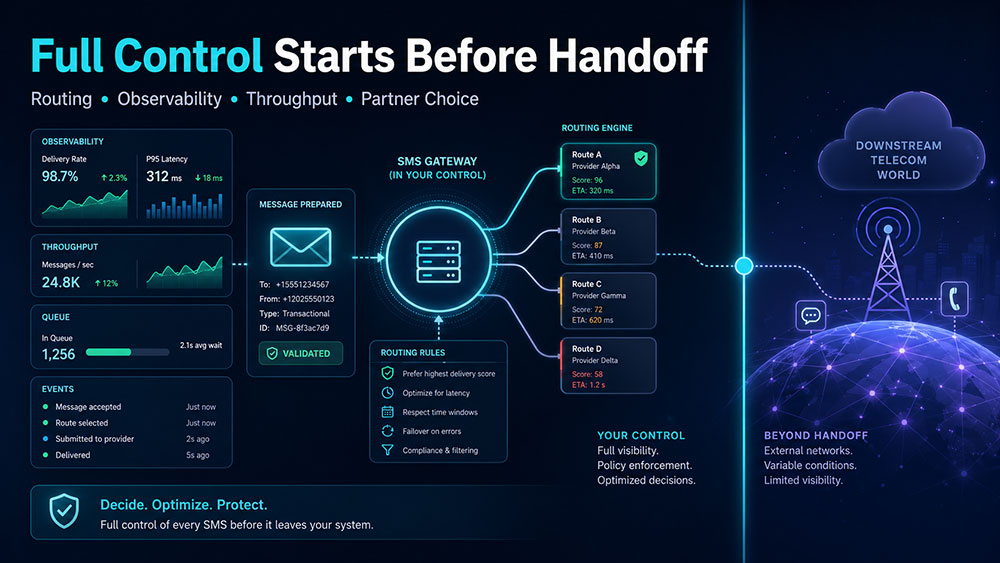
With the right SMS gateway architecture, control is not about pretending the outside world is predictable. It is about making sure that your own handling, routing logic, observability, and partner selection are not the weak point.
That is where modern infrastructure makes the difference.
Control where it actually matters
In SMS operations, there is a part of the flow you fully own, and a part you do not.
You cannot directly control what happens deep inside every downstream route once traffic leaves your environment.
But you can control:
- how messages are handled before handoff
- which routing rules are applied
- which partner or connection is selected
- how throughput is managed
- how retries and queueing are handled on your side
- how much visibility your team has into message flow
- how quickly operational teams can understand and adjust behavior
This is the real meaning of control.
It is not theoretical. It is operational.
A gateway should give you the ability to decide how traffic leaves your platform, under which conditions, through which path, and with what logic behind that decision.
If you cannot do that clearly and confidently, then your messaging stack is already compromised before delivery even begins.
Why “full control” is really about pre-delivery handling
Many messaging teams are forced to work with systems that hide the most important parts of the process.
A message is submitted.
A route is selected.
A status comes back.
But the logic in between is often opaque.
Teams may not know:
- why one route was chosen over another
- whether a rule was triggered correctly
- how traffic is being distributed
- whether throttling is applied intelligently
- whether performance issues begin inside their own setup
- whether a bottleneck is internal or downstream
That kind of uncertainty creates operational blindness.
And when messaging supports OTPs, alerts, or critical business notifications, blindness is expensive.
This is why control starts before the message leaves your system.
If the infrastructure on your side is transparent, flexible, and observable, then your team can act with confidence. If it is rigid or opaque, then you are already guessing before the SMS even reaches the external network.
Routing control is not a luxury
Routing is one of the clearest examples of meaningful control.
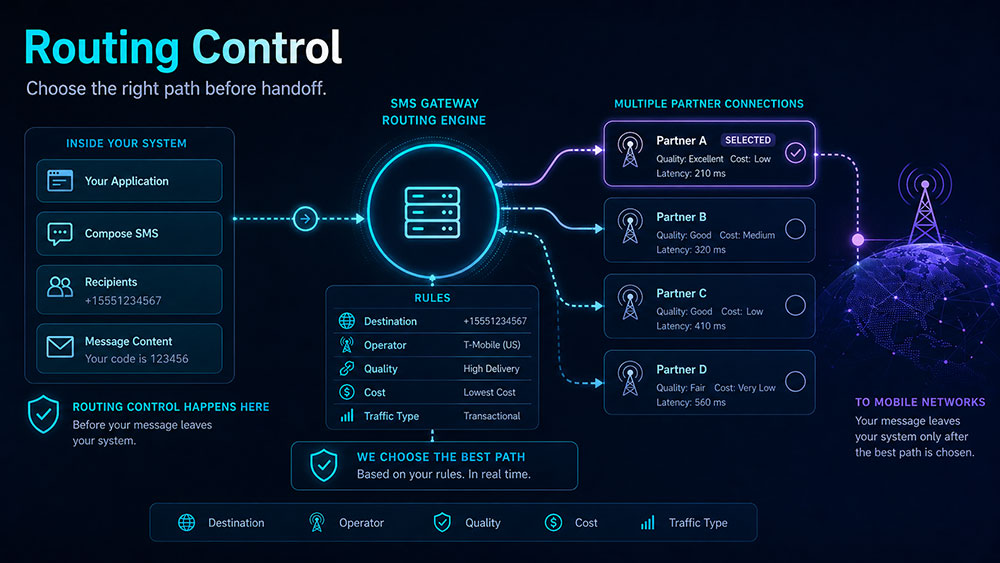
A modern SMS gateway should not force all traffic through a fixed path with little or no visibility.
It should allow operators to define routing logic based on business and technical priorities such as destination, operator, prefix, quality, cost, or traffic type.
That matters because routing decisions shape everything that follows.
If you have full control on your side, then you are also in a position to decide through which partner your traffic will leave your environment.
And that decision has consequences.
Choosing the right downstream path is not a cosmetic optimization. It is a reliability decision.
Observability of rules and decisions matters just as much
Control without visibility is incomplete.
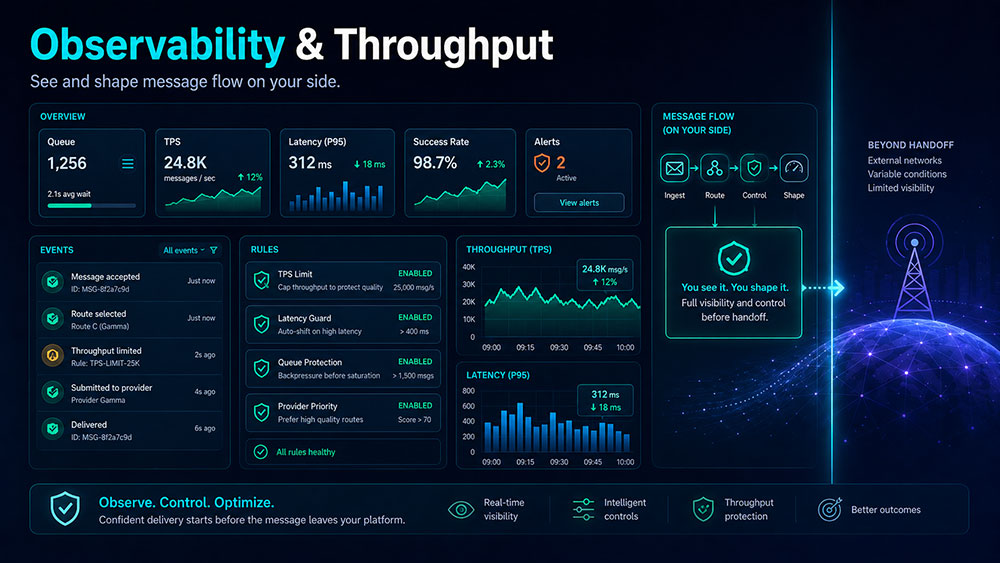
It is not enough to define rules. You also need to understand how those rules behave in production.
That means being able to see:
- which rule was applied
- why the message followed a specific route
- how the system handled the message before handoff
- where delays or queue build-up began
- whether throughput controls were triggered
- whether the behavior matched your intended policy
Weak observability turns even a flexible system into a difficult one to operate.
Strong observability turns routing logic into something your team can trust, audit, and improve.
This is especially important at scale, where small inefficiencies quickly become larger operational problems.
Throughput control is part of reliability
Throughput bottlenecks are often discussed as if they are purely downstream problems.
They are not.
While downstream congestion is real, your own side of the infrastructure also plays a major role in how traffic is paced, queued, and handed off.
That is why throughput control matters.
If your gateway allows proper rate control per connection, intelligent queueing, and predictable handling under load, then you can reduce avoidable bottlenecks before messages ever leave your platform.
You cannot eliminate every external delay.
But you can make sure your own system is not contributing unnecessary instability.
That is the difference between hoping traffic behaves well and engineering it to behave better.
Partner choice changes the quality of what happens next
Once a message leaves your system, your level of direct control ends.
But your partner choice determines a lot about what happens after that point.
This is where full control on your side becomes strategically important.
Because if your platform gives you routing autonomy, then you can make deliberate decisions about who carries your traffic.
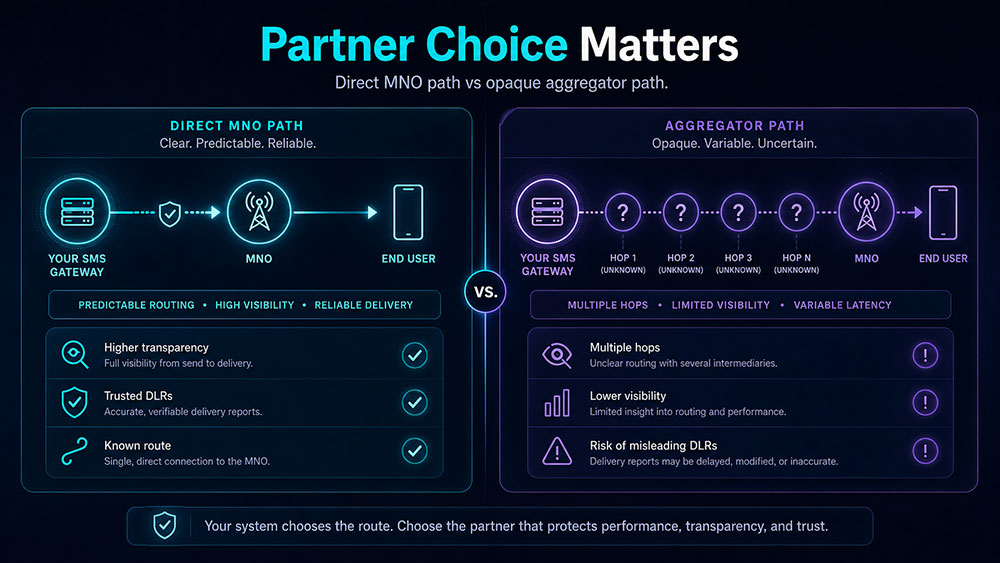
For example:
If traffic goes directly to an MNO
The path is generally more predictable.
Delivery reports are more likely to reflect real downstream events rather than artificially reassuring responses. Delays, when they happen, are more likely to remain within normal operational conditions, except during periods of unusually high traffic such as Black Friday, Christmas, or other major seasonal peaks.
This does not mean problems never happen.
It means the path is typically more transparent and more grounded in real network conditions.
If traffic goes through an aggregator
The path may become much less visible.
In some cases, you may not truly know how the message is traveling downstream, through which intermediate relationships, or how reporting is being generated.
That lack of transparency introduces risk.
One of those risks is the possibility of misleading or unreliable delivery reporting, including fake DLR scenarios. Another is inconsistent latency caused by routing choices you do not see and cannot verify.
This is exactly why control on your side matters so much.
You may not control the whole route after handoff, but you should absolutely control who you hand off to.
“Delivered” is still useful, but context matters
A delivery report still has value.
But its value depends on the quality and transparency of the route behind it.
A “delivered” status means much more when it comes through a trusted, predictable downstream relationship than when it comes through a chain you cannot properly inspect.
So the real question is not only:
Did I get a DLR?
It is also:
- Who did I send through?
- Why was that path selected?
- How much trust do I place in that downstream reporting?
- Did my own system handle traffic correctly before handoff?
That is a far more operationally mature way to think about SMS reliability.
What modern SMS infrastructure should make possible
If your messaging stack is built for real operational control, your team should be able to answer questions like these with confidence:
- Which route did this message take out of our system?
- Why was this route selected?
- Which rule matched?
- Which partner did we hand off to?
- How was throughput controlled before handoff?
- Did queueing begin on our side or downstream?
- Can we change routing logic quickly when priorities shift?
- Can we favor quality, cost, geography, or operator strategy depending on use case?
These are the questions that separate a basic gateway from infrastructure that is truly usable in production.
Final thought
In SMS, full control does not mean controlling everything after the message leaves your hands.
It means controlling everything that should be under your control before it leaves.
That includes your routing logic.
Your observability.
Your throughput handling.
Your operational transparency.
And your choice of downstream partners.
You may not own the entire delivery chain.
But you should absolutely own the decisions made before hand-off.
Because that is where reliability begins.
And that is where infrastructure like Sendium OS SMS Gateway creates real value:
not by claiming control over the whole world, but by giving operators full control over the part that is actually theirs to control.